Raymii.org

אֶשָּׂא עֵינַי אֶל־הֶהָרִים מֵאַיִן יָבֹא עֶזְרִֽי׃Home | About | All pages | Cluster Status | RSS Feed
C++ std::async with a concurrency limit (via semaphores)
Published: 09-01-2021 | Last update: 10-01-2021 | Author: Remy van Elst | Text only version of this article
❗ This post is over four years old. It may no longer be up to date. Opinions may have changed.
Table of Contents

Semafoor en Dommel
std::async is an easy way to do multiple things concurrently, without the
hurdle of manual thread management in C++. Like batch converting images,
database calls, http requests, you name it. Create a few std::futures and
later on when they're ready, .get() 'm while they're still hot. A future
is an object which handles the synchronization and guarantees that the results
of the invocation are ready. If you .get() it and it's not ready, it will block.
Recently I had a use case for concurrency with a limit. I needed to do hundreds of HTTP calls to a JSON API. The concurrency limit was not for the hardware, but for the server on the other side. I didn't want to hammer it with requests. But you can also imagine that you're converting images or other "heavy" processes which might be taxing for the hardware. If in doubt, always benchmark.
The end result, async tasks with a concurrency limit
There is no standard way to limit the amount of concurrent jobs via std::async.
You can fire of a hundred jobs and it is up to the implementation to not fry the
hardware. On linux/gcc it will probably use a thread pool so you're lucky, but
you cant assume that.
This article will show you a simple short solution to implement a concurrency
limit together with std::async, by using a Semaphore, implemented with
modern (C++ 11) standard library features (std::mutex, std::condition_variable and such).
It also has a C++ 17 version which replaces our custom CriticalSection
class with the use of an std::scoped_lock and implementing the BasicLockable
Named Requirement.
We start off with a shorter example showing how to fire off a set number of jobs and wait until all of those are finished before continuing. That is very useful if you have a set number of jobs and want the implementation to handle all the thread work for you.
I was introduced to Semafoor in my childhood by the Dutch (Belgian)
cartoon Dommel, or Cubitus in the USA. The series tells the story of
Cubitus, a good-natured large, white dog endowed with speech. He lives in a
house in the suburbs with his master, Semaphore, a retired sailor, next door
to Senechal, the black and white cat who is Cubitus' nemesis.
If you need these "advanced" concurrency features you could also just resort to
manual thread management. However, that is quite a bit more work to pull
off and for simple use cases std::async is just easier and simpler to setup and
use. This Semaphore adds a bit of complexity, but IMHO it's worth it, small enough
and still better than manual thread management.
Mutexes and Semaphores
Mutexes (mutual exclusion) and semaphores are similar in use and are often used interchangeably. I'll try to explain a the meaning in our C++ setup.
First a bit on what they share. Both a semaphore and a mutex are constructs that blocks execution of threads under certain conditions. Most often they are used in a "critical section" of code, that can have only one (or only a few) threads working on it at a time.
When a mutex or semaphore is available, a thread can acquire (lock) the mutex or semaphore and continue executing the "critical section".
When a mutex or semaphore is not available (locked), a thread is blocked from further execution when it wants to acquire/lock it. Threads that have acquired a mutex or semaphore must release it so another thread can (eventually) acquire it again. If that does not happen or if threads are waiting on one another, there is a deadlock.
The difference between a mutex and a semaphore is in our case that only one thread at a time can acquire a mutex, but some preset number of threads can concurrently acquire a semaphore.
A semaphore is used for flow control / signaling, (to restrict the number of threads executing the critical section).
In our case, the semaphore has a limit of 4, so when 4 threads have acquired
the semaphore, new threads must wait (are blocked) until the semaphore is available
again (once one of the 4 releases it). The waiting is all handled by C++ language
constructs (condititon_variable, lock_guard)
By using RAII, we can create an object named CriticalSection,
which acquires the semaphore when it is constructed (comes into scope) and
releases it when it is destructed (goes out of scope). Very handy since that
way you can never forget to manually release the semaphore.
Project setup
For this guide I assume you're running on a Linux system with gcc and cmake.
This is my CMakeLists.txt file:
cmake_minimum_required(VERSION 3.10)
project(async-with-max-concurrency)
set(CMAKE_CXX_STANDARD 11)
find_package(Threads REQUIRED)
add_executable(${PROJECT_NAME} main.cpp)
target_link_libraries(${PROJECT_NAME} Threads::Threads)
Thank you to Matthew Smith for showing me this over set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -pthread" ).
Quoting the advantages:
It's more portable (supports Win32 threads) and it will only set it for your target, instead of for every target in your project.
As always with cMake projects, create a build folder and configure cmake:
mkdir build
cd build
cmake ..
If you are ready to build the project, do a make in that folder:
make
The binary is located in the same build folder:
./async-with-max-concurrency
Queue up jobs and wait until they're all finished
This is a simpler example to get us started. Imagine yourself having to
get 15 JSON API endpoints, /api/v1/page/0.json up to 14.json to
process that information. You could write a for loop, which is fine
and simple. Doing 15 HTTP calls takes a few seconds, if one of them
is slow, the entire gathering part is slower overall. Wouldn't it be
nice if you could fetch those 15 pages at once? One slow page doesn't
slow the entire process down much.
Here is where std::async comes to the rescue. You create a bunch of
std::future objects that do the actual work and fire them off. Once
they're all finished, you can proceed.
This example does not make use of a semaphore or locking, it just fires off a set number of threads and lets the implementation manages
The code below fills a vector with future objects that return a
string. It uses a special template function to check if the futures
are ready, and if so, puts the result in another vector.
You can only .get() a future once. If it's not ready, that call blocks.
By using this template to check the state of the future, we ensure
that it is ready when we do the .get(), not blocking our execution.
// main.cpp
template<typename T>
bool isReady(const std::future<T>& f) {
if (f.valid()) { // otherwise you might get an exception (std::future_error: No associated state)
return f.wait_for(std::chrono::seconds(0)) == std::future_status::ready;
} else {
return false;
}
}
std::string timeString(std::chrono::system_clock::time_point t, const std::string& format) {
time_t timepoint_time_t = std::chrono::system_clock::to_time_t(t);
char buffer[1024];
struct tm tm {0};
if (!gmtime_r(&timepoint_time_t, &tm)) return ("Failed to get current date as string");
if (!std::strftime(buffer, sizeof(buffer), format.c_str(), &tm)) return ("Failed to get current date as string");
return std::string{buffer};
}
int main() {
int totalJobs = 15;
std::vector<std::future<std::string>> futures;
std::vector<std::string> readyFutures;
// Queue up all the items,
for (int i = 0; i < totalJobs; ++i) {
futures.push_back(
std::async(std::launch::async,
[](const std::string& name){
std::this_thread::sleep_for(std::chrono::seconds(1));
return "Hi " + name + ", I'm an example doing some work at " +
timeString(std::chrono::system_clock::now(), "%H:%M:%S");
}, std::to_string(i))
);
}
// wait until all are ready
do {
for (auto &future : futures) {
if (isReady(future)) {
readyFutures.push_back(future.get());
}
}
} while (readyFutures.size() < futures.size());
for (const auto& result : readyFutures) {
std::cout << result << std::endl;
}
return 0;
}
I'm explicitly using parameters in the lambda to show what is being passed around. If you don't like lambda's you can also use variadic arguments to call another function:
std::string ExampleJob(int tally) {
return "Hi " + std::to_string(tally) + ", I'm an example doing some work at " + timeString(std::chrono::system_clock::now(), "%H:%M:%S");
}
// main {}
futures.push_back(std::async(std::launch::async, ExampleJob, i));
If you create a std::async this way and want to pass a parameter by
reference, you need to use std::ref() (read why here). So if you want to
pass a reference to a string (const std::string& myString), you would do
std::async(std::launch::async, ExampleJob, std::ref(myString)).
The above code results in the below output:
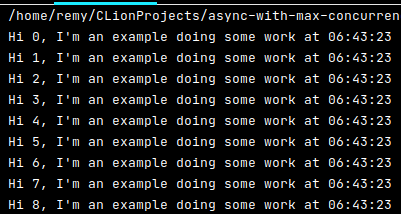
I've added a helper function to print a time string. In this example all the "jobs" run at the same time, but in the next example you should see a delay there.
This example is useful if you have a set number of items you need to work with, or if you want the implementation to manage all the threads for you. On my workstation I can queue up 1500 of these example jobs and they all run the same second. 15000 jobs take 10 seconds to give you an idea.
Job queue with a concurrency limit
This is what you probably came here for so lets get into this job queue with a
concurrency limit. We're using a std::condition_variable to do all the hard
work for us. Quoting cppreference:
The condition_variable class is a synchronization primitive that
can be used to block a thread, or multiple threads at the same time, until
another thread both modifies a shared variable (the condition), and notifies
the condition_variable.
The purpose of a std::condition_variable is to wait for some
condition to become true. This is important, because you actually do need that
condition to check for lost wakeups and spurious wakeups.
We could also have used a polling loop to implement this waiting, but that would use way more resources than this, and would probably be more error prone.
How to use the condition_variable is almost spelled out to us on cppreference,
so do go read that. If you're wondering about the technical details behind using
a unique_lock, this stackoverflow post has the best explanation.
Now onto the code. The first class, the Semafoor (Dommel reference here) does the
actual work, count is it's max limit of concurrent threads. The second class,
CriticalSection, is a handy dandy RAII wrapper. In its constructor it
waits for the Semafoor (which in turn, when possible, acquires the lock) and
in its destructor it releases the Semafoor (which in turn, releases the lock).
See the last part of this article for a C++ 17 feature, the std::scoped_lock
which replaces our CriticalSection.
That translates to, as long as your scope is correct, you never forget to lock or
unlock the Semafoor.
// main.cpp
class Semafoor {
public:
explicit Semafoor(size_t count) : count(count) {}
size_t getCount() const { return count; };
void lock() { // call before critical section
std::unique_lock<std::mutex> lock(mutex);
condition_variable.wait(lock, [this] {
if (count != 0) // written out for clarity, could just be return (count != 0);
return true;
else
return false;
});
--count;
}
void unlock() { // call after critical section
std::unique_lock<std::mutex> lock(mutex);
++count;
condition_variable.notify_one();
}
private:
std::mutex mutex;
std::condition_variable condition_variable;
size_t count;
};
// RAII wrapper, make on of these in your 'work-doing' class to
// lock the critical section. once it goes out of scope the
// critical section is unlocked
// Note: If you can use C++ 17, use a std::scoped_lock(SemafoorRef)
// instead of this class
class CriticalSection {
public:
explicit CriticalSection(Semafoor &s) : semafoor{s} {
semafoor.lock();
}
~CriticalSection() {
semafoor.unlock();
}
private:
Semafoor &semafoor;
};
template<typename T>
bool isReady(const std::future<T>& f) {
if (f.valid()) { // otherwise you might get an exception (std::future_error: No associated state)
return f.wait_for(std::chrono::seconds(0)) == std::future_status::ready;
} else {
return false;
}
}
std::string timeString(std::chrono::system_clock::time_point t, const std::string& format) {
time_t timepoint_time_t = std::chrono::system_clock::to_time_t(t);
char buffer[1024];
struct tm tm {0};
if (!gmtime_r(&timepoint_time_t, &tm)) return ("Failed to get current date as string");
if (!std::strftime(buffer, sizeof(buffer), format.c_str(), &tm)) return ("Failed to get current date as string");
return std::string{buffer};
}
int main() {
int totalJobs = 15;
std::vector<std::future<std::string>> futures;
std::vector<std::string> readyFutures;
Semafoor maxConcurrentJobs(3);
// Queue up all the items,
for (int i = 0; i < totalJobs; ++i) {
futures.push_back(
std::async(std::launch::async,
[](const std::string& name, Semafoor& maxJobs){
CriticalSection w(maxJobs);
std::this_thread::sleep_for(std::chrono::seconds(1));
return "Hi " + name + ", I'm an example doing some work at " +
timeString(std::chrono::system_clock::now(), "%H:%M:%S");
}, std::to_string(i), std::ref(maxConcurrentJobs))
);
}
// wait until all are ready
do {
for (auto &future : futures) {
if (isReady(future)) {
readyFutures.push_back(future.get());
}
}
} while (readyFutures.size() < futures.size());
for (const auto& result : readyFutures) {
std::cout << result << std::endl;
}
}
In main() not much has changed. I'm again explicitly using parameters in the
lambda to show what is being passed around. We create a Semafoor with a
concurrent limit of 3, pass a reference to that into the lambda, and,
most important, when our work starts we create a CriticalSection object,
that acquires the Semafoor or waits until it is available. When that goes
out of scope, the Semafoor is released.
If you use this code, you can put your own critical section in {} (curly brackets) to limit that scope:
some();
code();
{ // scope starts
CriticalSection w(SemafoorRef); // Semafoor acquired
do();
work();
} // scope ends there, Semafoor released
more();
code();
If you don't want to use a lambda you can pass a function when creating the
std::future, but the Semafoor has to be a reference (they all must use
the same Semafoor), thus we need to pass a std::ref(), like so:
std::string exampleJob(int tally, Semafoor& maxJobs) {
CriticalSection w(maxJobs);
std::this_thread::sleep_for( std::chrono::seconds(1));
return "Hi " + std::to_string(tally) + ", I'm an example doing some work at " + timeString(std::chrono::system_clock::now(), "%H:%M:%S");
}
[...]
futures.push_back(std::async(std::launch::async, exampleJob, i, std::ref(maxConcurrentJobs)));
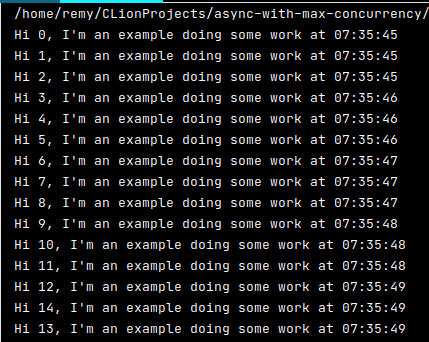
The code outputs the following:
As you can see, the timestamps now have a second between them each 3 jobs,
just as we said. The Semafoor has a max concurrency limit of 3, which the
code and output reflect. Only 3 jobs are running at the same time. You must
make sure to use the same semaphore everywhere, otherwise you'll be copying
one and each instance has their own unique semaphore, which is exactly not
what we want.
For jobs where you do need some parallelism but need more control than
std::async provides you, whilst not having to result to manual threads,
using this semaphore construction gives you just enough control. In the case
of my HTTP requests, I didn't overload the server but limited the requests to
15, but you can think of many more use cases (converting files, database
actions, you name it).
C++ 17 with a scoped_lock
Soon after publishing this article I got a great email from Chris Tuncan
discussing premature optimization and a new feature in C++ 17, the
std::scoped_lock (cppreference).
The scoped_lock basically replaces the CriticalSection class, as long as
the Semafoor implements the minimal characteristics of the Named
Requirement BasicLockable, .lock() and .unlock().
It has one more advantage, it has a variadic constructor taking more than one mutex. This allows it to lock multiple mutexes in a deadlock avoiding way. But since we're only using one mutex, that's not applicable to us. Still wanted to mention it since it is great to have that in the standard library.
If you are using C++ 17 you can omit the CriticalSection class and replace all
usage by a scoped lock. In the above example you would replace this line:
CriticalSection w(maxJobs);
by this:
std::scoped_lock w(maxJobs);
Also you must update the C++ standard to 17 in your CMakeLists.txt:
set(CMAKE_CXX_STANDARD 17)
That's all there is to it. You get the advantage of using multiple mutexes if
you ever need it, and as we all know, the best code is the code you can delete
easily later on, so go ahead and replace that CriticalSection by a
std::scoped_lock. Or, if you're not lucky enough to have a modern compiler
like most of us, go cry in a corner on all the cool language stuff you're
missing out on...
More comments from Chris
Quoting Chris on the premature optimization, he responds to my statement in the opening
paragraph On linux/gcc it will probably use a thread pool....
If we cannot assume the implementation uses a thread pool, and instead spawns a thread per
std:asynccall, AND if you intent is to prevent lots of threads being launched, then we would need to add an extra layer of complexity. Currentlystd::asyncis calledtotalJobstimes, with or without the semaphore. Just with theSemafoorall butmaxJobsof those threads would go to sleep. We'd end up needing some sort of queue of jobs to pass tostd::async, any you'd need to wrapasyncso you don't have to block createdasync jobs, and ..., and ....Eurgh, that ruins all the simplicity of your solution, and is definitely a case of premature optimisation!
I agree with both points. Easy for me to assume GCC, but premature optimization is also a pitfall. For this articles purpose, the problem is not spawning too many threads but overloading the computer or remote server (either hundreds of concurrent requests or turning your computer into a space heater when converting a million photos at the same time).
Thank you to Chris for both points of feedback and the code examples. I'd not yet worked with Named Requirements explicitly, exploring them will be fun.
Tags: async , c++ , cmake , cpp , development , mutex , semaphore , threads , tutorials