Raymii.org

אֶשָּׂא עֵינַי אֶל־הֶהָרִים מֵאַיִן יָבֹא עֶזְרִֽי׃Home | About | All pages | Cluster Status | RSS Feed
The Twitter Bitcoin hack can happen anywhere humans are involved
Published: 31-07-2020 | Author: Remy van Elst | Text only version of this article
❗ This post is over five years old. It may no longer be up to date. Opinions may have changed.
Table of Contents
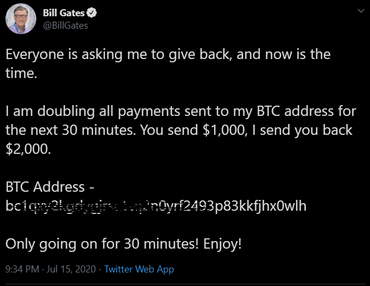
The recent twitter hack involved social engineering and access to the twitter backend. This opinion piece will show you that this sort of incident can happen everywhere as long as humans are involved.
Everywhere there are manual actions or admin / backend panels, this can happen. Pay a support-slave enough and they'll delete an account 'by accident'. Or a rougue sysadmin that disables logging, does something horrible and enables logging again. Or a sales person giving 100% discounts and disable reporting.
I hope that this piece makes you think about the things that can go wrong at your company and hopefully you take time to fix it or get it fixed. Or at least mitigate risks, add some more logging, train your staff, treat them well, etcetera.
The ars technica article has screenshots of the aledged backend:
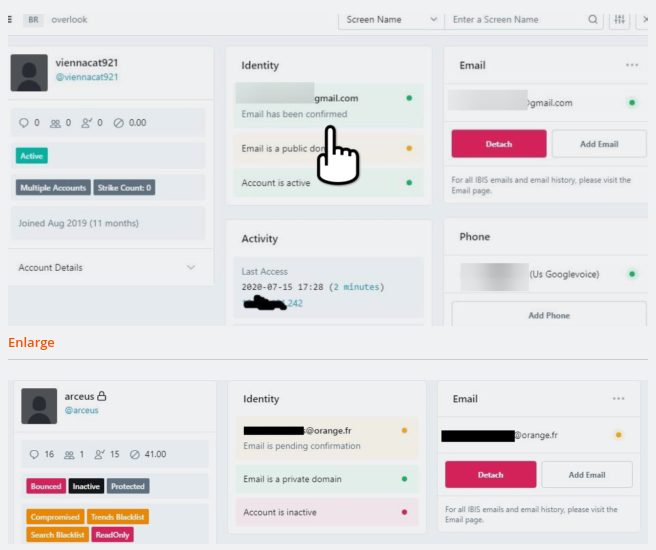
I'll show you that there is no one size fits all solution. Or at least, not a single fix for all. Treating your employees well, educatingthem on risks and automating as much as possible will get you a long way."
Humans are involved, thus things can go wrong
If you have missed it, just recently very prominent twitter accounts started to tweet a bitcoin scam. "Transfer bitcoins to here and I'll pay you back the double amount", in some form or other. As twitter themselves state, their staff was social engineered and thus access to their internal systems was gained.
My guess is that it's way more easy / cheaper to scam a low level support person or to offer them a sum of cash to cause an "accident" than to search for vulnerabilities, exploit one and island-hop further into a network and then execute such an action.
There might not be anything malicious going on, it could just be an actual successfull phising action. Sucks to be the one that got phished, but the company probably lacked user security training, or two factor authentication, two ways to mitigate phishing.
However, imagine yourself being a low level, low paid IT support person with a slight grudge against the company. It would be a nice revenge to cause public havoc, or get ransomware inside, or by accident delete important data, while being able to claim you made an honest mistake, either because of social engineering or because the manual procedure you were executing should have been automated away years ago.
Now each and every company I've worked for has had these backend panels. Most of the time these are built as an aftertought when you grow big enough to hire support or clercs, lack the same validation / security measures as the customer facing self service side or there are still manual procedures to be done by helpdesk staff, which require high level permissions, because automating it takes more time than just instructing Joe from the helpdesk to not make mistakes.
Each and every other company has these backends and every company also has staff that can abuse them, willingly or by accident.
Technical measures for people problems
As they say, security is like an onion, it stinks and makes you cry. Or, maybe they mean the layers part. If you train your users, patch your software, have a web proxy / outgoing filter, strict firewall/vpn, restrict executables, run antivirus and mandate two factor auth, you make it harder for hackers (and for your employees), but not impossible. Just as with regular burglars, you only have to be more secure than your neighbor is in most cases.
If you have none of the above, chances are you've already been hacked but don't know it. If you do have all of the above, you still can get hacked. Then you hopefully have proper (offsite) logging in place to reconstruct what happened.
Even with logging it will still cause damage to the company, reconstruction takes time, backups take time to restore and the damage is already done, causing much inconvinience.
Technical measures only go so far in solving people problems. Train all your users on phising. The hospital I worked at did a massive phising email once a year to over fifteen thousand staff, each year they saw less and less people filling in their passwords due to awareness training.
But, if there is malicious intent, it might be hard to see if it was an accident or malicious on purpose. Here's another example I've had happen in one of my companies.
Imagine a sales person being able to assign a discount, which is a regular part of his job. He sees that every month a report of all the discounts goes to the sales manager, for checks and balances. But, by accident, he gives a 100% discount, and next month doesn't see it on the balance sheet. Maybe because the reporting software never was written for a 100% discount. Now, six months later, he's has himself a little side business, where he gets paid directly by some shady customers, who all have 100% discount but stay under the radar. This can go on forever, until the report is changed, some other staff member sees the accounts or because someone talks. But by then this person is long gone with the wind, and if caught, could just claim it was a typo / bug.
Solution?
In my humble opinion, there is no one size fits all solution. However, splitting the problem up into seperate categories, solutions come to mind. Both technical and people-wise.
Phising and related security attacks (ransomware):
- Train your employees regularly on security, phising etc.
- Have a proper, fine grained, security infrastructure in place.
One other big thing is to not have a "blame" culture. If employees are likely to be mistreated after making a mistake, they will cover it up. If you have an open culture where mistakes can be made and you try to learn from them, people are more open to admitting failure, which in the long run is better for everyone.
Manual procededures that allow for accidents to happen
- Automate them, at least bare minimum make sure users can make no catastrofic errors.
- If you don't automate them, have a runbook with step by step, almost copy paste instructions, and a document describing what do to when mistakes are made.
- Log everything in such a way you can reconstruct why errors happened.
- Have regularly tested backups for when things do go wrong.
Disgruntled or malicious employee, "accidents"
- Treat your employees well, if they have no reason to go rougue, they are less likely to do so.
- Have fine grained logging in place
- Make sure no employee can go rougue, by having reports or audits done regularly by others.
Conclusion
Everywhere humans are doing work, mistakes are made. Twitter was breached due to social engineering, but the question to ask is, did staff actually need all those extra rights which the hackers abused? Was there a way that, even with hackers inside, not all keys to the kingdom where lost right away?
Manual procedures, disgruntled employees and security risks all allow for mistakes to happen. Mistakes with large consequences, mistakes that maybe are on purpose and things that shouldn't have happened at all if there was proper tooling in place.
Can you fix it? No, not entirely. You can however get a long way in making sure it doesn't come to it, and if it does come to it, have proper measures of reconstructing what happened.
Not all measures are technical, training, checking and treating people well go a long way. Technical measures can help, but as far as I'm concerned, they cannot entirely replace people measures.
What follows are a few scenarios and procedures I've come accross in my carreer.
My examples of backends and manual procedures
In the following paragraph I'll show you one of the backends I worked with, give you examples of manual procedures and what can go wrong with them.
By showing these scenarios and the ones above, I hope that you can think of the things in your organization that can be improved.
In my career as a sysadmin I've worked with many different sorts of companies, as you can see on the about page. Most of the stories are not applicable anymore due to procedure changes, policy changes or software updates. Some information is masked, but you still get the general idea.
Every company with Active Directory
Every company with a fleet of windows computers probably uses active directory to manage users, computers and policies. 90% of those companies have in house or external helpdesk which users can call to reset their password.
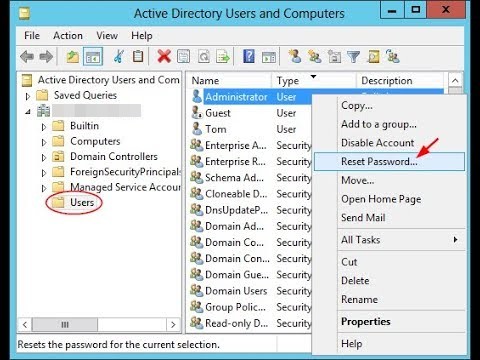
The above dialog window is all that you need to do to reset a users password. Now there are policies and rights you can manage to let only certain people reset passwords, but I suspect that your average company just allows the IT helpdesk to reset passwords for everyone. If you're lucky you have a self service portal, but who remembers those recovery questions anyway...
After the rougue IT intern has reset the password of the CEO friday evening, he emails a few of the biggest customers, informing them they're like the backend of a horse, he resets the twitter password and tweets nasty things on the CEO's account and sends Sally from finance a few PDF's and requests to pay big amounts to his bank account. On sunday he's out of state and was never heard from again. Or, he claims to have been on vacation, and it turns out the culprit was another IT admin you fired recently, but who still had access because of passwords not changed.
Hospital
In the hospital I worked at the electronic medical records were first stored in a system named ZIS (ziekenhuis informatie systeem). It was a self written operating system for the PDP-11 from the seventies, as a research project for a few large hospitals in the Netherlands. Ported to VAX and when I worked there it was running on linux machines. Here is a dutch PDF describing the migration from VAX to UNIX to LINUX. When active, it served every hospital digital task, from the finances, to the kitchen, to the lab and all related to patient care. It had it's own Wordperfect-like text editor for patient letters (TEKST) and everything you could think of related to hospital patient care.
{kind=link}
{kind=link}
I can talk about this system because it has been phased out a few years ago.
Every IT staff had an administrative account which allowed them to kill user sessions (telnet wasn't the most reliable), reset printers and see everything for every patient. Here are a few screenshot of the manual procedure to reset a printer:

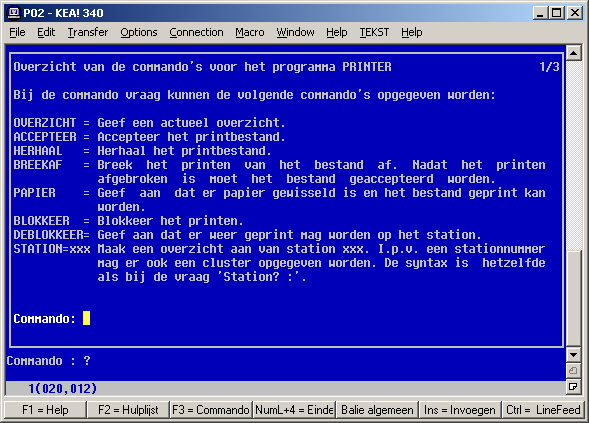
First you had to edit the hosts file (either with a line editor (edl/eds)
like ed or search, an interactive version) to find the printer IP address
(tcp/ip was added in later on in the systems lifetime, before that everything was
connected via serial lines), then in another program (aptly named PRINTER), you
had to reset it via a sequene of commands in an interactive menu.
One time, I even had zis crash with a stacktrace:
Here's a picture of my user account from back when I was still at university for my nursing degree:
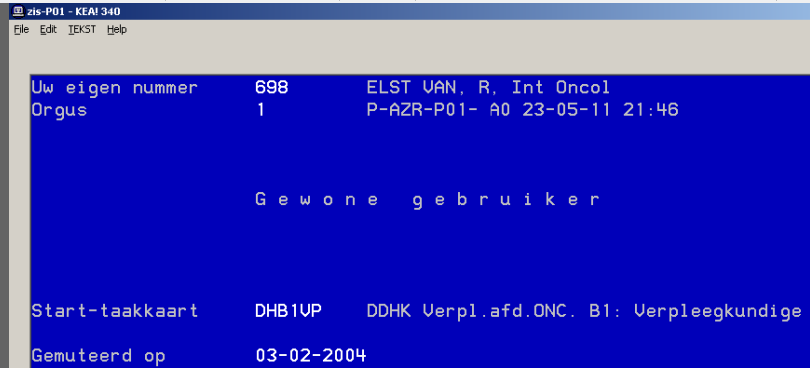
Here is another screenshot of the program we used to print medication stickers:
I studied both nursing and computer science, and worked in the hospital in both roles. But back to the printer issue. As you can see on the picture, you edited the system wide hosts file. If you wanted, you could remove lines relating to other things than just printers, like computers on patient departments used by nurses to login, or other servers (database etc.). Because printer resetting was a common occurence, after every paper jam you had to reset it, even interns could execute this action. As far as I know it never went wrong, but if you screwed up the hosts file, you could cause a huge impact to the system. Not to mention other privileged actions like killing user sessions, editing patient records or removing imaging data.
In the semi-graphical UI based on ZIS, IT staff could even remove patients:
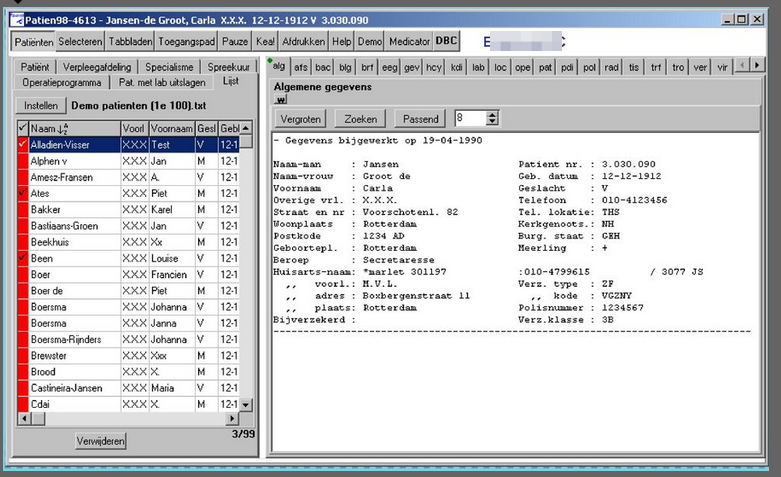
That was because at some point in time regular staff were able to duplicate patients, but not remove them. The duplication button was later removed, but the permission for IT staff wasn't.
One point to note here is that a lot of permission was granted based on verified trust. Proper logging and backups were in place and to even be able to work there you had to have a VOG (Verklaring omtrent gedrag). A dutch government (justice department) issued statement telling that you had no earlier offences. It was specific for the job required, so if you are a convicted pedophile you won't get a VOG for a childcare job, but you might get one for a cab driver job. If you were convicted for drunk driving, you won't get one for a cab driver job but could get one for a childcare job.
For IT related jobs, at least in the hospital, categories checked were handling of sensitive data / documents and general convictions as far as I remember.
A few years ago, ZIS was phased out, finally, after 40 years, in favor of some self written oracle based software, which was later replaced by Chipsoft HIX.
The history of ZIS is so interesting and innovative that I might do an article on it in the future.
Tags: admin , backend , blog , security , social , twitter